1、数字后端综述
1、数字后端综述
1.1 数字系统芯片设计
首先简述全流程:
系统设计 -> 功能验证 -> 逻辑综合 -> 物理实施
1.1.1 设计流程
首先给出设计的流程图
IP级设计 -> 系统级设计 -> 逻辑综合 -> 版图规划 -> 总线规划 -> FCT Budget -> Pin指定 -> 电源规划 -> 时钟规划
IP级设计
购买/设计IP,得到RTL代码文件
系统级设计
把RTL代码划分为block,有些要把几个IP划分为一个block,有些把一个IP划分为多个block。划分为block后,它们仍然是以RTL代码的形式存在的。
逻辑综合(logic synthesis)
把每个block的RTL代码分别综合成一个个网表文件,此时它们的文件形式从RTL代码文件变成了Netlist文件。但是它们仍然以block划分。
版图规划(Floor Plan)
在版图上根据block之间关系的密切程度,规划block在版图上的位置、面积等,力求在面积、易于接线方面的合理性。即:既要达到面积最小,又要方便后续的接线。
总线规划(Bus Plan)
完成版图规划后,把总线的走向、走法规划好,每一个block都必须考虑到。
FCT Budget
Pin指定(Pin Assignment)
对于每一个block,它们pin的位置、方向都是需要指定的,这一步要根据走线的结果来定。
电源规划(Power Plan)
把每一个block的功耗信息都做上标记。(究竟是功耗问题,还是电源线的规划?)
时钟规划(Clock Plan)
规划时钟树。这一步分为不同的层级,包括block level和chip level。block level只能看到少数的几个层,chip level能看到的层数更多,通常是全部层。
时钟规划需要充分考虑到各个模块的延时,从而确保时钟信号到达对称模块或者相互间有关系的模块时,时钟之间的不同步不至于让芯片失效。
以上所有项目都需要由专门的工程师负责,每位工程师/每个团队的职能都不同。
1.1.2 Block PnR流程
什么是PnR?
PnR是Place and Route的缩写(我猜的),是将综合后的block放置在版图上,并完成走线的过程,应该可以简称为布局布线。注意,布局和布线是两个过程,而不是一个。
设计数据
这个步骤主要是对一些文件进行辨别,这些文件具有不同的后缀名,或者具有不同的属性。
- Netlist
网表文件是RTL代码综合的结果,它保存了各个器件之间的互联信息。注意,这里是对各个block的RTL代码综合的结果,所以Netlist仍以block的形式存在。
- def
保存了block的形状和面积信息,也包括电源网络和macro的位置。
- lib
分为logic library和physical library
logic library:保存了信号通过某一个门产生的延时。
physical library:保存了门的大小和形状信息。
- delay
保存了信号通过一个逻辑块/网表内的电路造成的延时。这点和lib文件中的logic library是不一样的。
- tf
保存了晶圆厂(Foundry)给的设计物理规则,是设计时必须加载的文件。
布图规划 Floor plan
检查def
如果有def,可以直接用def文件进行布图规划,因为里面已经保存了每个block的形状和面积。如果没有def,则需要初始化floor plan,自行创建def文件。
创建def
在没有def的情况下,需要手动创建def。首先需要初始化floor plan。
放置macro
接着开始摆放macro,所谓的macro是相对于STD(标准器件)而言的,它主要是一些非标准的IP,需要手动摆放。一个设计中可能有很多macro,所以要把它们都摆放到floor plan里面。
电源规划
除了VDD之外,还有VSS或者其他电压需要布线,要做好电源规划。另外,这些电源也要连接衬底/阱等需要保持某个电压的部分上。
导入physical cell
logical cell是指带有逻辑功能的单元,它强调的是逻辑功能。而physical cell强调物理。
然后,将这些macro固定在版图上。
布局
把STD标准器件摆放到摆放区域。
时钟树综合(CTS)
尽管这个时候的时钟树布线都是理想状态,每条线的延迟为0,但还是要尽量保证延时不出问题。从时钟树的树根(root)到每一个块的clk pin的延时latency无偏差或者尽可能小,即skew尽可能小。
布线
以晶圆厂所给的设计规则进行布线。
简单的静态时序估算
RC提取
抽取出RC delay,用于静态时序分析
静态时序分析(STA)
布线后优化
物理设计验证
物理验证包括两部分,LVS、DRC、PFM。
LVS,用于确保版图和电路的一致性。
physical DRC,主要是保证满足晶圆厂提供的物理要求,比如最小线宽要求、最小间距要求。
PFM,良率检查。
逻辑等价检查
检查在以上步骤完成后,是否有逻辑上的偏差。理论上,经过这些设计后,它们的逻辑功能是不应该发生改变的。
设计“签核”
确认无误后,才可以核签。
1.2 物理设计
1.2.1 物理设计的主要问题
物理设计主要解决几个问题:
时序(Timing)
是物理设计中的重要一步,主要还是保证时序不影响逻辑。
DRC(Foundry)
物理规则检查,由晶圆厂给的物理规则。
信号完整性(SI)
随着线宽的不断缩小,信号完整性检查也变得越来越重要。在信号线平行经过的地方,如果一条线的频率过高,他就会对周围并行的线进行攻击,导致其他线的延时或者信号值发生改变,这种现象叫做cross talk,中文可以叫串扰。这是由信号线之间的寄生电容造成的。一般说来,信号完整性分析对时序正确也有很大影响。
判断一个信号是否保持完整、未被串扰,需要做两点检查:
- 信号异常跳变的面积是否过大
- 信号跳变的高度是否过大
以上两点都会对信号完整性由很大影响。
设计收敛
必须保证每次PnR或者修改设计后,总体的效果是往好的方向(收敛)进行的,而不能越修改越差。关于这一点,需要更多地去实践。
时序收敛
功耗
静态功耗
静态泄露功耗
从VDD到VSS之间的功耗。
动态功耗
翻转功耗
翻转过程对电容、寄生电容充放电的功耗。
导通功耗
状态转换过程中,当触发器/反相器等模块中的CMOS处在在VDD的90%和10%的电压之中时,会有两管同时导通的情况,这个功耗取决于持续时间的长短,这个时间称为transition time。这个时间一般需要约束,而且需要分别考虑时钟信号CLK和数据信号DATA。
注意,这个transition time并非做得越小越好。一般来说,如果希望transition time变小,需要付出其他代价,比如换用波形更好的buffer、在设计时增加buffer等,会增大buffer占用的面积等。有些追求是得不偿失的,所以只要满足设计所需的要求就可以,这里主要是要在面积和功耗之间灵活取舍。
IR-drop,EM
当电源经过了拥有大量触发器flip-flop的区域(通常是以“行”的形式存在的),而且这个区域的触发器同时翻转时,造成的瞬间大电流会让这片区域降落的电压远高于接下来其他触发器较少的区域,使后面的区域输入电压变小。这就是IR-drop。电压减小可能会导致后面区域的电压失效,进而导致整个芯片的功能失效。
EM指的是电迁移,Electronic Migration。在电流不减小而线宽减小的情况下,电流密度会越变越大。于是电子流会不断冲击金属中的某些薄弱区域,导致断路,使芯片失效。
DFM
DFM指的是可制造性设计。
例子:dummy metal
当金属层中,金属线的分布不均匀,甚至不同区域在金属数量上差距悬殊时, 在制造时为了防止在化学腐蚀、机械抛光过程中带来的磨损程度不同的问题,需要在金属较少的区域插入一些dummy metal,使不同区域的金属密度一致。这些金属不具备任何电气功能,不与任何信号线路连接,他主要是为了让整片芯片在制造时磨损速率保持一致,提高良率。
这只是其中一个例子,可制造性设计还有很多其他例子。一般来说,这一步在很多情况下只需要执行一条命令就可以了。
1.2.2 PR工具的解构
数据系统
OA是一种数据格式,由cadence公司推出的一种开源数据格式,它是用来记录网表的一种数据格式,也就是说,OA由网表文件Netlist转换而来。OA有一个很方便的地方,就是可以直接用Python或者Perl读取。
milkyway是ICC的一个物理库,后面会提到。
优化引擎
ICC有三种优化引擎:逻辑优化、布图优化和布线优化。布局、布线过程中,都会有个优化引擎让时序(timing)能够符合原来的逻辑功能。
分析引擎
ICC有三种分析引擎:时序分析、功耗分析、噪声分析,即Timing、Power、SI Timing。
Flow框架
Flow可以理解为流程,那么Flow框架也就是流程框架。有一个专门的团队会负责这个框架,这个团队叫做CAD Team。这个团队会将数据准备(data preparation)、版图规划(Floor Plan)等步骤,一直到布局布线(PnR)、DRC、LVS等步骤都放进Flow中,他们会写完这些代码。PnR(这里是指数字后端工程师)只要执行几行代码,就可以执行完布局布线的工作了。那么PnR工程师主要是干什么的呢?主要是要对返回的结果进行分析,然后对分析的结果做优化。
尽管前面的步骤不归后端工程师管,CAD团队会写完整个流程的代码,但还是要了解他们用的命令是什么。
另外,小公司并不一定有CAD团队,所以这些工作有时候也会让后端工程师兼职。写一个简单的flow,有助于知晓每一步需要用到哪些命令,有助于理解。
一些关键词
Timing:时序问题
Hard IP Placement : 其实Hard IP就是指之前的Macro,也就是非标准的那些IP。
Congestion : 是一个指标,用来Placement之后,在Route之前,评估Route问题的指标。如果Congestion指标存在问题,说明之后布线可能会存在问题。当然, 这个仅供参考,不一定真的存在问题。
SI : 噪声问题
skew : 偏差问题
OCV : on chip variation,用来指定芯片测试时的PVT条件。这里的PVT并不是指P压强,V体积、T温度,而是指Process、Voltage、Temperature。芯片在制造过程中会有一定的偏差,即使是相同的产品线下来的芯片也会有不同的地方。所以,芯片应该被分为不同的Process,有时这个Process可以指芯片的响应时间、温度差之类的东西,它分为TT、SS、FF三种,它们对应平均情况、最差情况和最好情况。Voltage就是指电压,Temperature是指温度。这三种指标结合起来,会产生很多种不同的情况,我们需要确保测试出芯片在每一种情况下的表现。OCV就是用来衡量这种系统级误差测试完成情况的。
SDC : 时序约束
1.3 数据准备
数据准备主要是分为两部分。一部分是逻辑部分logic,一部分是物理部分physical。
对于标准单元(Standard cells)、非标准IP单元(Macro cells)和触点单元(Pad cells)来说,都有这么两部分。
| logic | physical | |
|---|---|---|
| Standard cells | db文件 | mw文件 |
| Macro cells | db文件 | mw文件 |
| pad cells | db文件 | mw文件 |
| 约束文件orca.sdc | 技术文件abc_6m.tf | |
| 门级网表orca.v | RC参数模型文件(TLU+) | |
| 综合数据 | 物理数据 |
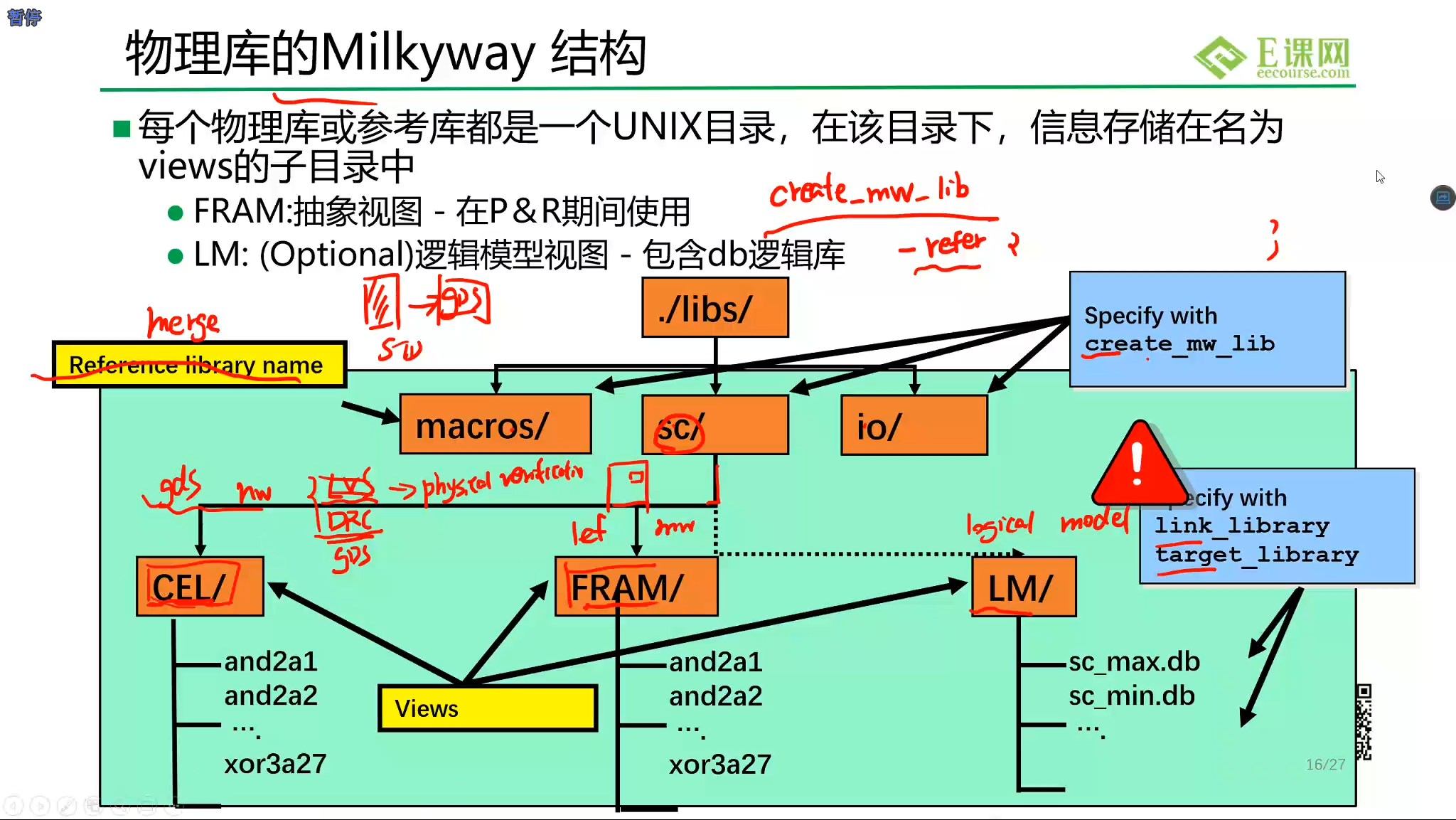
物理库文件
这里的MW文件指的就是MilkyWay文件,里面存的都是二进制内容,人类不可读,但只要知道它是存着物理信息就可以了。这是由工艺厂商提供的,ICC独有的文件。
工艺厂商可能会给lef文件和gds文件。这两个文件的内容如下:
| 物理信息 | 内部结构 | |
|---|---|---|
| lef | 有 | 无 |
| gds | 有 | 有 |
lef和gds同样是二进制文件。他们可以转换为MilkyWay文件,供ICC使用。他们之间不同的是,gds中已经不仅记录了芯片形状和pin等外部信息,还记录走线等详细的内部结构,但lef只提供形状和pin这些外部结构。
技术文件是厂商提供的文件,记录了物理规则。
RC模型参数文件后缀是TLU,记录了RC参数,主要是线的RC参数。厂商提供的一般是itf文件,需要转换成TLU文件才能给ICC使用。
这里有个没列出来的文件:nxtgrd文件,是静态时序分析时用的文件,是给Prime Time静态时序分析软件(PT)用的格式。TLU和nxtgrd本质上是一样的。
物理库中还规定了:放置单位走线(placement unit tile)、放置线的高度(placement rows)、最小宽度(Minimum width resolution)、首选的走线方向、走线轨道的宽度等等信息。
逻辑/时序库文件
逻辑库中的3个db文件是由厂商提供的lib文件转换而来的,这不归PnR管。里面包含的都是些:
- 标准单元的时序和功能信息
- 硬核的时序信息
- 驱动drive和负载load的设计规则:最大扇出/最大转换时间(transition)/最大、最小电容
学完本课后要求会:
操作软件读取orca.sdc约束文件、orca.v门级网表、abc_6m.tf技术文件、TLU参数模型文件
逻辑库读入方法:用变量指定link_library和target_library。
link_library是走线时使用的,它会将网表中的元器件按照这张表连起来。
target_library是优化使用的,会在走线优化的时候读入。
物理库使用命令指定:
create_mw_lib -mw_reference_library