6、UVM机制(一)
6、UVM机制(一)
6.1 UVM类
记住这个结构就行,如果需要知道详情,可以去看张强《UVM实战》这本书,真的强烈推荐。

6.2 factory机制
什么是factory机制
“
UVM factory机制可以使用户在不更改代码的情况下实现不同对象的替换。
factory是UVM中一种数据结构。它的作用范围是整个平台空间,它有且仅有一个实例化对象(即单实例类)。它是一个多态构造器,可以仅仅使用一个函数让用户实例化很多不同类型的对象。
为了使用一个函数而可以返回多种对象,这些对象必须从一个基类扩展而来。
”
例如,从my_transaction扩展出my_transaction_ext,创造不同的输入数据、输入数据范围等,从而达到不同的验证效果。
factory机制中的两个查找表
factory机制的核心是两张查找表,一张叫注册表,一张叫替换表。
首先是注册表。在诸如driver、env这些component中, 都有这样一段代码:
`uvm_component_utils(class_name)
而transaction(sequence也是,只是它同时用了field机制才需要begin、end)这样的object中,有这样一段代码:
`uvm_object_utils(class_name)
这两个都是用于向factory注册的宏。当component或者object调用注册宏后,就向注册表中加入了这些类。在实例化对象时,使用类似于这样的语句:
// 在build_phase中实例化
m_env = my_env::type_id::create("m_env", this);
才能使factory机制生效,而不是直接使用构造函数new。另外,注册还有一个好处,就是可以在函数中调用一些已经定义好的静态函数(例如get_type),而不用自己定义。
其次是替换表。
在实例化对象时,UVM会扫描替换表中的类,查看正在实例化的类是否已经被其他类替换。如果没有,就使用当前类例化。如果查找到被替换了,就用替换的类实例化。
向注册表注册需要用以上两个宏,向替换表中写入内容也需要由相应的宏来完成,这就是override宏。
override机制
使用factory机制能提升验证平台的复用性,其中一个原因在于factory机制中的override机制。
override能够将通过重写或者继承原来的类创造的新类覆盖掉原来的类,从而实现验证平台的复用。
override语句主要有两个:
// 这一句是整体替换,会把整个验证平台中的目标类被替换成新的类。
set_type_override_by_type(original_class_name::get_type(),
target_class_name::get_type());
// 这一句是部分替换,只会把其中一个对象替换成新类的对象。
set_inst_override_by_type("original_inst_path",
original_class_name::get_type(),
target_class_name::get_type());
这两个函数都只存在于component中,也就是说仅有component才能调用这两个函数去替换类,而且一般需要在build_phase中调用它们。
override用法
假设我现在要替换的是transaction A,要将它替换成transaction B,替换前的transaction情况:

首先看set_type_override_by_type,看一下这句语句的示意图:

可以看到,整体被替换成了transaction B,实现方法如下:
// 1. 将transaction A扩展为transaction B
class transaction_B extends transaction_A;
// 需要重新注册
`uvm_object_utils(transaction_B)
// 重写构造函数
function new(string name = "");
super.new(name);
endfunction
// 2. 如果是要修改限制条件,需要重写修改的部分,不需要写未修改的部分。
// 注意,新的限制条件一定要在旧的限制条件之内,就是子集,不能比原来的限制条件更宽。
constraint Limit_new{
xxxx;
}
endclass
// 3. 在组件中调用set_type_override_by_type替换,
// 例如可以用原来的testcase扩展为新的testcase,
// 这里示意性地把testcase_A扩展为testcase_B,直接从uvm_test扩展也是可以的
class testcase_B extends testcase_A;
// 需要重新注册
`uvm_component(testcase_B)
// 重写构造函数
function new(string name = "", uvm_component parent);
super.new(name, parent);
endfunction
// 4. 在build_phase中,写入替换信息
virtual function void build_phase(uvm_phase phase);
super.build_phase(phase);
set_type_override_by_type(transaction_A::get_type(),
transaction_B::get_type());
endfunction
// 可以通过一些打印信息来确定是否确实替换成功了
virtual function void report_phase(uvm_phase phase);
super.report_phase(phase);
factory.print();
endfunction
endclass
// 最后,在top中启动run_test时,填入testcase_B,就能正确启动了。
然后再看看set_inst_override_by_type。这是替换后的示意图:

下面是实现方法,可以看出和set_type_override_by_type非常类似:
// 1. 同样地将transaction A扩展为transaction B
class transaction_B extends transaction_A;
// 需要重新注册
`uvm_object_utils(transaction_B)
// 重写构造函数
function new(string name="");
super.new(name);
endfunction
// 2. 同样使用限制条件作为不同点
constraint Limit_new{
xxxx;
}
endclass
// 3. 同样,在组件中调用set_inst_override_by_type替换,
// 例如可以用原来的testcase扩展为新的testcase,
// 这里示意性地把testcase_A扩展为testcase_C,
// 直接从uvm_test扩展也是可以的。这边只替换sequencer中的transaction。
class testcase_C extends testcase_A;
// 需要重新注册
`uvm_component(testcase_C)
// 重写构造函数
function new(string name = "", uvm_component parent);
super.new(name, parent);
endfunction
// 4. 在build_phase中,写入替换信息,需要注意的是这个路径,起点是自身,所以不用写,
// 终点是被替换对象所在的component或者它的父对象,比如这里的索引就到m_seqr了。
// 如果路径只写到m_env,就会把m_env中所有的transaction_A对象都替换掉,这不一定符合预期。
// 所以要搞清楚替换对象到底在哪里。
virtual function void build_phase(uvm_phase phase);
super.build_phase(phase);
set_inst_override_by_type("m_env.i_agent.m_seqr.*",
transaction_A::get_type(),
transaction_B::get_type());
endfunction
// 可以通过一些打印信息来确定是否确实替换成功了
virtual function void report_phase(uvm_phase phase);
super.report_phase(phase);
factory.print();
endfunction
endclass
// 最后,在top中启动run_test时,填入testcase_C,就能正确启动了。
再次强调:
- 只能在component中调用override,但被替换的类可以是component或者object。
- 替换的类和被替换的类必须有一定的继承关系,比如新类继承自旧类。
如果不在EDAplayground使用,没有把这所有代码都放在一个design.sv的文件里的话,需要调用include把新增的代码文件都包含进来。
这里只是做了一个transaction激励替换的例子,用这个方法还可以替换平台组件,改变测试平台组件的行为。以后有时间了也写下来。
6.3 field机制
field机制的应用
下面是my_transaction代码:
class my_transaction extends uvm_sequence_item;
rand bit [3:0] rxd;
rand bit rxv;
// 重点关注这段代码!
`uvm_object_utils_begin(my_transaction)
`uvm_field_int(rxd, UVM_ALL_ON)
`uvm_field_int(rxv, UVM_ALL_ON)
`uvm_object_utils_end
// 我是说上面这段!
constraint Limit{
rxd inside {[0:15]};
}
function new(string name = "");
super.new(name);
endfunction
endclass
可以看到这段代码中有一段调用了`uvm_object_utils_begin和end的代码块。这段代码有两个作用:
- 向factory注册my_transaction类,这点和普通的不带begin和end的代码是一样的。
- 为begin和end中包围的这些变量(比如这段里写的是rxd和rxv)在类中创建一些实用的方法,例如打印、复制、对比、打包、解压、记录等,这就是field automation机制。简单来说,就是可以用UVM的内建函数处理数据,而不用自己手动编写具有这些功能的方法(函数)。
要让变量具有这些方法,需要用这几个关键语句:
`uvm_field_int()
`uvm_field_queue()
这些宏必须被包括在uvm_object_utils_begin和end之中才能使用。component也具有相同的宏,只需要把这些语句包含在uvm_component_utils_begin和end里就行。
UVM field automation机制的内建方法
| 方法名 | 功能 |
|---|---|
| clone | 深度复制,如果被复制的目标成员中包含了其他对象,就调用该对象的clone也复制一份,这种方法是会创造新对象的。该方法仅限于使用了UVM field automation机制的成员。 |
| copy | 普通复制,如果被复制的目标成员中包含了其他对象,不会调用该对象的copy方法,仅对句柄进行复制,而没有创造新的对象。该方法仅限于使用了UVM field automation机制的成员。 |
| 按照给定格式打印出对象的成员,打印的内容仅限于使用了UVM field automation机制的成员。 | |
| sprint | 与print类似,但返回的是一个字符串 |
| compare | 深度对比,对比的内容仅限于使用了UVM field automation机制的成员。 |
| pack | 将成员按一定格式打包成一个数据流,打包的内容仅限于使用了UVM field automation机制的成员。 |
| unpack | 按成员的规格对数据流进行分解,参与分解的成员仅限于使用了UVM field automation机制的成员。 |
| record | 对成员做记录,参与记录的成员仅限于使用了UVM field automation机制的成员。 |
如果在类中有某一个成员没有赋予field automation机制,那么这些方法都对它不起作用。
成员变量的注册方法
大部分变量注册的格式都为:
`uvm_field_*(ARG, FLAG)
其中ARG是变量名,FLAG指屏蔽类型(等一下讲),这里的*一般填入数据类型,比如int,或者int_queue,也就是队列,等等。
但有一种类型的数据例外:枚举类型enum。
`uvm_field_enum(T, ARG, FLAG)
T为枚举类型的名字,ARG为变量名,FLAG为屏蔽类型。
这里记录一些常用的宏,需要的时候可以来这里查找,不需要特别记忆:
`uvm_field_int(ARG, FLAG)
`uvm_field_real(ARG, FLAG)
`uvm_field_enum(T, ARG, FLAG)
`uvm_field_object(ARG, FLAG)
`uvm_field_string(ARG, FLAG)
`uvm_field_array_enum(ARG, FLAG)
`uvm_field_array_int(ARG, FLAG)
`uvm_field_array_string(ARG, FLAG)
`uvm_field_queue_int(ARG, FLAG)
`uvm_field_queue_string(ARG, FLAG)
`uvm_field_aa_int_string(ARG, FLAG)
`uvm_field_aa_string_string(ARG, FLAG)
关键词:UVM field automation成员对象注册方法表
FLAG标识符
类中的每个成员都可以设置它们是否参与某个操作,比如rxd不参与复制,但rxv参与复制等。用来设置这些行为的就是FLAG标识符。
FLAG本质上是一个15位的向量,可以手动地定义这样的向量,然后放在FLAG的位置。还可以用UVM中已经定义好的一些宏,去规定哪些功能开启,哪些功能关闭:
UVM_DEFAULT
// 将所有机制都打开,该成员参与所有方法,一般都用这个就可以
UVM_ALL_ON
// 是否参与复制
UVM_COPY
UVM_NOCOPY
// 是否参与比较
UVM_COMPARE
UVM_NOCOMPARE
// 是否参与打印
UVM_PRINT
UVM_NOPRINT
// 是否参与记录
UVM_RECORD
UVM_NORECORD
// 是否参与打包
UVM_PACK
UVM_NOPACK
在调用打印的时候,可以指定特殊的打印格式,打印格式有如下几种:
UVM_BIN
UVM_DEC
UVM_UNSIGNED
UVM_OCT
UVM_HEX
UVM_STRING
UVM_TIME
UVM_REAL
使用方法:
`uvm_field_int(field, UVM_ALL_ON | UVM_BIN)
加上这个按位或就行。
6.4 configuration机制
configuration机制个人感觉是应用难度比较大,却能极大地增加验证平台重用性的机制。作为验证平台属性配置的机制,它的强大主要体现在它所能传递的数据类型上:
- 它能传递一般的值,可以是整型、实数、队列等,用于配置一些散布在验证平台中的可配置参数。
- 传递对象。传递对象最经常的用途是拿它来配置整个平台。
- 传递interface,接口。class中不能直接使用interface创建新的接口,只能在内部定义一个虚接口virtual interface,然后由外部传入。
configuration机制的优点
- 可以简单地配置某个组件中变量的值,避免外部使用全局变量带来的风险
- 高层组件可以在不改变代码的情况下改变子组件的变量
- 各个层次都可以使用configuration机制,限制小
- 支持通配符和正则表达式
- 支持用户自定义的数据类型
- 可以在仿真运行的过程中进行配置
configuration原理
UVM configuration实现分为两部分:
设置配置资源(set,可以理解为发送):
调用相关代码后,会把配置内容写入UVM配置资源池中,这类似于一种表格,也类似于factory两张表中的替换表,但他需要的信息更多。
使用静态函数设置:
uvm_config_db#(type)::set(
uvm_component cntxt, // 资源来源,必须是component
string instance_name, // 资源去向,描述这个资源所属的组件,是一个字符串,可以用通配符或者正则表达式
string field_name, // 资源的ID,相当于通道名,是其他组件获取这个资源的重要凭证
T value // 资源值,可以是值、对象或者接口
);
获取配置资源(get,可以理解为接收):
设置完资源后,尽管UVM资源池内已经记录了数据来源、数据类型、数据去向、资源的ID、资源值这么5项内容,但不代表它已经配置成功了。要想配置成功,还必须在适当的位置获取这些资源。
使用静态函数获取:
uvm_config_db#(type)::get(
uvm_component cntxt, // 获取配置资源的源组件,在何处获取资源
string instance_name, // 被配置的目标对象所在的组件,是个字符串,可用通配符和正则表达式
string field_name, // 资源的ID,要和设置时填入的ID一致
inout T variable //
);
传递值例子:为sequence配置资源
获取配置资源
一般来说,sequence中有控制产生随机transaction个数的量。可以让这个量设置成一个变量,然后使用configuration机制从外部去配置,从而实现产生transaction数量的控制。
展示修改后的sequence代码:
class my_sequence extends uvm_sequence#(my_transaction);
`uvm_object_utils(my_sequence)
// 用于控制产生transaction数量的变量,默认值还是填上比较好
int item_num = 10;
function new(string name="");
super.new(name);
endfunction
// pre_randomize函数是systemverilog的内容,
// 总之它会在随机化前调用,不由phase控制。
// 用静态函数get接收数据
function void pre_randomize();
uvm_config_db#(int)::get(
// config只能发送东西给平台组件component,而sequence并不是component,
// 只能发送给它的父对象m_seqr。
// sequence父对象类是my_sequencer,注意这里写得是父对象的类而不是父对象本身
my_sequencer,
// 这里是空的,因为就是取到本地
"",
// 第三个是资源ID,需要和set时的参数相同,可以用变量名作为ID,方便记
"item_num",
// 配置的目标对象,这里就把数据交给item_num就可以
item_num
)
endfunction
virtual task body();
if(starting_phase != null) begin
starting_phase.raise_objection(this);
// 替换掉这里的数
repeat(item_num) begin
`uvm_do(req)
end
#100;
if(starting phase != null) begin
starting_phase.drop_objection(this);
end
end
endtask
endclass
设置配置资源
因为sequence中配置了它将从m_seqr中获取数据,所以这边需要发送数据给到m_seqr。记住资源的ID,就是第三个参数,要和获取的一致才行。这里将从顶层去配置这个在sequence里的item_num。
class my_test extends uvm_test;
// 注册
`uvm_component_utils(my_test)
my_env m_env;
// 构造
function new(string name="", uvm_component parent);
super.new(name, parent);
endfunction
// build
virtual function void build_phase(uvm_phase phase);
super.build_phase(phase);
m_env = my_env::type_id::create("m_env", this);
uvm_config_db#(uvm_object_wrapper)::set(this, "*.m_seqr.run_phase", "default_sequence", my_sequence::get_type());
// 在这里设置item_num资源值
uvm_config_db#(int)::set(
// 资源源,是谁发送的数据,写this就行,从这里发送过去
this,
// 配置对象所属的component,是sequencer,即m_seqr,顺着向下找到它
"*.m_seqr",
// 资源ID,刚才说了是用变量名来做资源ID,便于记忆
item_num,
// 资源值,直接给个int类型的数就行,这里给20
20
);
endfunction
virtual function void start_of_simulation_phase(uvm_phase phase);
super.start_of_simulation_phase(phase);
uvm_top.print_topology(uvm_default_tree_printer);
endfunction
endclass
这样就完成了资源配置,把my_sequence的值设置成了20。
进一步理解config db的参数
这里还需要进一步理解config_db的参数。对于uvm_config_db#(type)::set()的四个参数:
uvm_config_db#(type)::set(
uvm_component cntxt,
string instance_name,
string field_name,
T value
);
cntxt,指的是context,是个UVM组件,而instance name是实例名的意思,它们放在一起将组合成可见范围。例如,如果填上这节所讲的参数,变成:
uvm_config_db#(int)::set(
this, // 这个this来自于my_test
"*.m_seqr",
item_num,
20
);
那么,可见范围就是my_test中的m_seqr及以下的部分。即,这条配置信息只对sequencer和它的子对象可见。当然, 第一个参数也可以填上null,那么在第二个参数中补齐可见范围即可:
uvm_config_db#(int)::set(
null,
"uvm_test_top.m_env.m_seqr",
item_num,
20
);
可见范围还是同样的,m_seqr和它的子对象。
为什么是uvm_test_top呢?因为不论启动怎么样的testcase(这里是my_test),UVM都会自动地把它的实例命名为uvm_test_top。
传递interface例子
interface,接口,是driver与DUT、monitor与DUT直接连接的部分,如图所示:
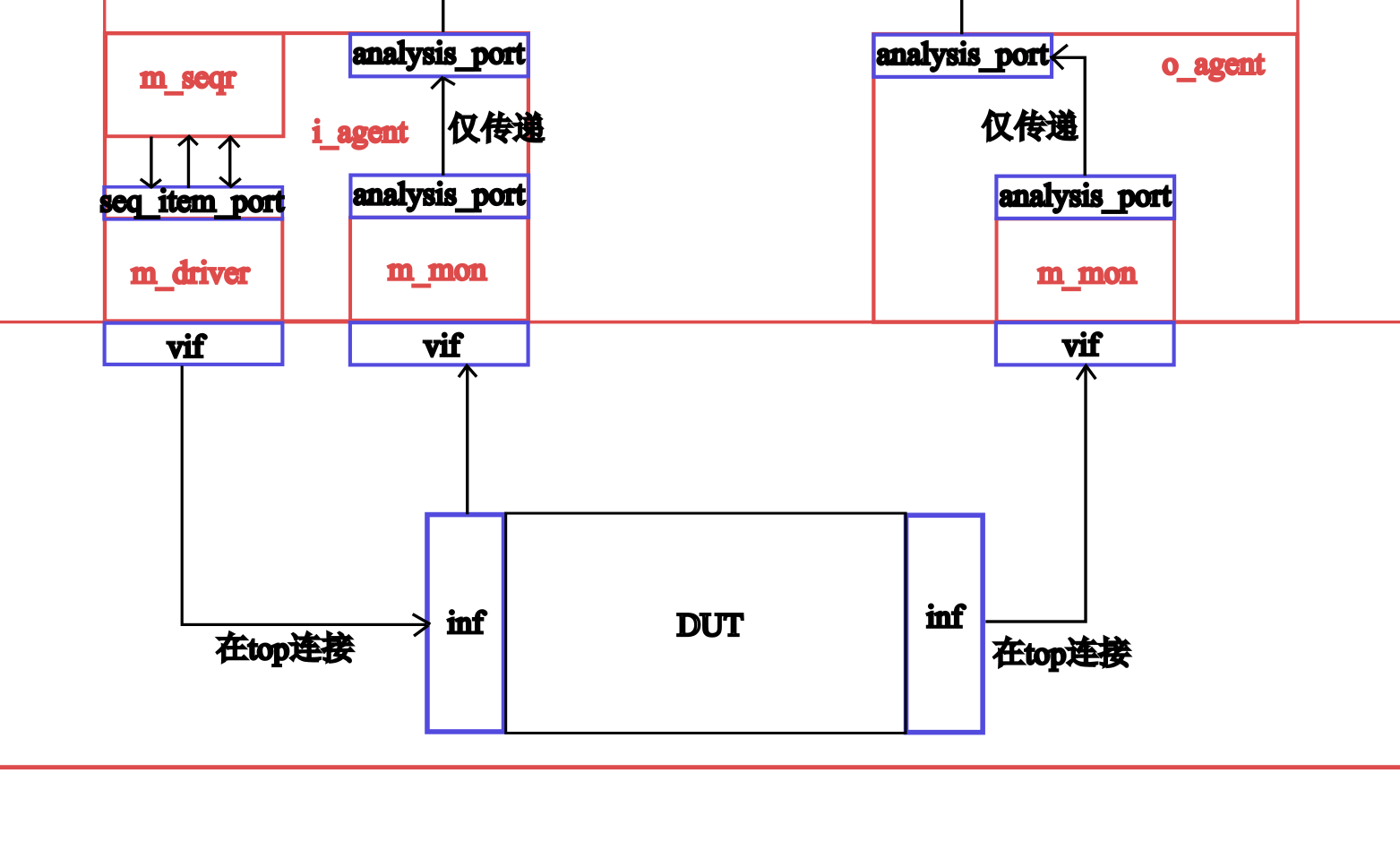
刚才已经说过,interface不能直接用于class中,所以需要建立一个虚接口virtual interface的句柄,这也是缩写vif的由来。虚接口不能直接例化,需要从外部接收,这就需要用到UVM configuration。
先看一下用于第二章所述DUT的interface的代码,这里不作详解:
interface dut_interface(
input bit clk
);
logic rst_n;
logic [3:0] rxd;
logic rx_v;
logic [3:0] txd;
logic txv;
clocking imonitor_cb@(posedge clk);
default input #1 output #0;
input rxd;
input rxv;
endclocking
clocking driver_cb@(posedge clk);
default input #1 output #0;
output rst_n;
output rxd;
output rxv;
endclocking
clocking omonitor_cb@(posedge clk);
default input #1 output #0;
input txd;
input txv;
endclocking
modport imonitor(clocking imonitor_cb);
modport driver(clocking driver_cb, output rst_n);
modport omonitor(clocking omonitor_cb);
endinterface
在driver中接收interface(在monitor中接收也是类似的):
class my_driver extends uvm_driver#(my_transaction);
`uvm_component_utils(my_driver)
// 声明一个虚接口句柄,用已经定义好的接口,在前面加上virtual即可
virtual dut_interface m_vif;
function new(string name="", uvm_component parent);
super.new(name, parent);
endfunction
// 接收接口到vif
virtual function void build_phase(uvm_phase phase);
super.build_phase(phase);
// 在build_phase中接收
uvm_config_db#(virtual dut_interface)::get(this, "", "vif", m_vif);
endfunction
// 驱动DUT的方法
virtual function void pre_reset_phase(uvm_phase phase);
super.pre_reset_phase(phase);
// 这是12个runtime phase之一,而且驱动DUT是需要消耗时间的,
// 所以需要提起objection,详见下一节。
// 在pre_reset_phase中,先把modport中属于driver的那部分给上不定态。
phase.raise_objection(this);
m_vif.driver_cb.rxd <= 4'bx;
m_vif.driver_cb.rxv <= 1'bx
// 不要忘记drop。
phase.drop_objection(this);
endfunction
virtual function void reset_phase(uvm_phase phase);
super.reset_phase(phase);
phase.raise_objection(this);
// 可以开始赋初值,这里给上reset后的值
m_vif.driver_cb.rxd <= 4'b0;
m_vif.driver_cb.rxv <= 1'b0;
phase.drop_objection(this);
endfunction
virtual task run_phase(uvm_phase phase);
// run phase不属于runtime phase,不需要继承,也不需要提起objection
// 根据接口协议,驱动DUT。这里的DUT只是一个简单的数据转发模块,所以只是简单地把数据发送到接口就行
// 接收transaction分解后发送给DUT
forever begin
seq_item_port.get_next_item(req);
// 打印一下收到的数据
`uvm_info("DRIV_RUNPHASE", req.sprint(), UVM_MEDIUM)
m_vif.driver_cb.rxd <= req.rxd;
m_vif.driver_cb.rxv <= req.rxv;
// 等待一个周期,打印已经驱动的信息后结束这组数据的仿真
@m_vif.driver_cb;
`uvm_info("DRIV_RUNPHASE", "Data has driven.", UVM_MEDIUM)
seq_item_port.item_done();
end
endtask
endclass
接口要在顶层实例化。由于program是不能实例化DUT的,所以需要在module中实例化。
"include 所有代码"
module top;
bit sys_clk;
dut_interface m_inf(sys_clk);
dut dut_inst(
.clk(m_inf.clk),
.rst_n(m_inf.rst_n),
.rxd(m_inf.rxd),
.rxv(m_inf.rxv),
.txd(m_inf.txd),
.txv(m_inf.txv)
);
// 时钟
initial begin
sys_clk = 1'b0;
forever #10 sys_clk = ~sys_clk;
end
// 给driver传递inf,这个接口还要传递给monitor,所以直接传给agent,
// 让monitor和driver都可见,再让它们分别从agent中取得就行
initial begin
uvm_config_db#(virtual dut_interface)::set(null, "*.m_agent.*", "vif", inf);
run_test("testcase");
end
// 产生波形文件
initial begin
// $wlfdumpvars();
// 在edaplayground中改用以下这两句:
$dumpfile("dump.vcd");
$dumpvars;
end
endmodule
传递对象例子
这是configuration机制中最难的例子。他需要新建一些类,用于配置整个验证平台。这是一种比较高级的用法。
暂时不给出这个例子的代码。一来验证平台到这里还不是那么复杂,其次,reference model和scoreboard还没有加入,没有这么多需要配置的类。
configuration机制可以传递用户自定义的类。当验证平台中需要配置的参数太多、太散的时候,对他们一个个单独使用set和get其实非常麻烦。
可以把这些所有需要配置的参数封装成一个配置类,让平台组件顶层先获取这个类,取出自己需要的数值,然后把余下的部分传递给子对象让他们配置,然后再传递给子对象的子对象取出数据完成配置,这样一层层地往下传,直到配置完整个平台。
那么,首先需要确定有哪些变量需要配置,这里举出几个例子:
env中:
is_coverage 是否需要进行覆盖率统计
is_check 是否需要加入scoreboard
agent中:
is_active agent是否为active模式
sequencer中:
item_num sequence产生的个数,其实不是sequencer本身需要,而是要传给sequence的,但只能由sequencer来接收
driver中:
vif 虚接口
monitor中:
vif 虚接口
假设就有这么些数据需要配置,而且在参数类往下传的过程中,先经过env,后经过agent,所以需要创建两个类,一个类名叫env_cfg,配置env,一个类名叫agent_cfg,配置agent,而且agent_cfg应该是env_cfg的子对象。
而driver、monitor因为已经是终端了,所以不需要再向下传,所以不需要再单独建立一个类。
// 配置文件一般扩展自uvm_object,而不是component
class agent_cfg extends uvm_object;
// agent 本身的配置数据,这些数据最好都给上初值,下同
is_active = UVM_ACTIVE;
// 给sequencer
item_num = 20;
// 给driver和monitor
virtual dut_interface m_vif;
// 因为配置数据需要复制,所以用field automation机制提供这些方法
`uvm_object_utils_begin(agent_cfg)
// 一种特殊的数据类型
`uvm_field_enum(uvm_active_passive_enum, is_active, UVM_ALL_ON)
`uvm_field_int(item_num, UVM_ALL_ON)
`uvm_object_utils_end
// 构造函数
function new(string name="");
super.new(name);
endfunction
endclass
然后再写env的配置文件:
class env_cfg extends uvm_object;
// env本身的配置数据,这些数据最好都给上初值
is_coverage = 0;
is_check = 0;
// 需要包含agent_cfg,先声明句柄
agent_cfg m_agent_cfg;
`uvm_object_utils_begin(env_cfg)
`uvm_field_int(is_coverage, UVM_ALL_ON)
`uvm_field_int(is_check, UVM_ALL_ON)
// 要把子对象的类也加进来
`uvm_field_object(m_agent_cfg, UVM_ALL_ON)
`uvm_object_utils_end
// 构造函数
function new(string name="");
super.new(name);
// 这里不用factory创建子对象,直接构造就行
m_agent_cfg = new("m_agent_cfg");
endfunction
endclass
在这一整个类和需要它的地方都需要声明一个句柄,用以接收config_db传递来的信息。
而在testcase这样的高层模块,则需要调用它的构造函数,而且需要配置这个配置类。
class my_test extends uvm_test;
`uvm_component_utils(my_test)
my_env m_env;
// 声明配置类句柄
env_cfg m_env_cfg;
function new(string name = "", uvm_component parent);
super.new(name, parent);
// 实例化配置类
m_env_cfg = new("m_env_cfg");
endfunction
virtual function void build_phase(uvm_phase phase);
super.build_phase(phase);
m_env = my_env::type_id::create("m_env", this);
uvm_config_db#(uvm_object_wrapper)::set(
this, "*.m_seqr.run_phase", "default_sequence", my_sequence::get_type()
);
// 给env_cfg和agent_cfg里的数值赋值
m_env_cfg.is_coverage = 0;
m_env_cfg.is_check = 0;
m_env_cfg.m_agent_cfg.item_num = 40;
// 需要传递的虚接口,需要从top获得,传递给配置类的m_vif,直接用句点就能表示它。
if(!uvm_config_db#(virtual dut_interface)::get(this, "", "top_vif", m_env_cfg.m_agent_cfg.m_vif)) begin
// 如果没有成功得到vif,就没必要继续了
`uvm_fatal("CONFIG_ERROR", "无法获得顶层传来的接口!")
end
// 传递配置类给env,接下来转到env去解包并继续向下传递
uvm_config_db#(env_cfg)::set(
this, "*.m_env", "env_cfg", m_env_cfg
);
endfunction
endclass
下面展示env类中,如何接收、解包配置自身,并把agent的配置信息传下去:
class my_env extends uvm_env;
`uvm_component_utils(my_env)
int is_coverage = 0;
int is_check = 0;
// 注意我这里用了m_agent,而不是之前的i_agent
my_agent m_agent;
// 需要声明接收配置类的句柄,不需要初始化
env_cfg m_env_cfg;
function new(string name = "", uvm_component parent);
super.new(name, parent);
endfunction
virtual function void build_phase(uvm_phase phase);
super.build_phase(phase);
m_agent = my_agent::type_id::create("m_agent", this);
// 接收来自testcase的数据,并保存到env_cfg里
if(!uvm_config_db#(this, "", "env_cfg", m_env_cfg)) begin
`uvm_fatal("CONFIG_ERROR", "无法获得来自testcase的接口!")
end
// 然后再把中间的agent_cfg传递给agent
uvm_config_db#(agent_cfg)::set(this, "*.m_agent", "m_agent_cfg", m_env_cfg.m_agent_cfg);
// 提示现在的覆盖率收集设置为开启
if(m_env_cfg.is_coverage) begin
`uvm_info("COVEARGE_ENABLED", "覆盖率收集已开启!", UVM_MEDIUM)
end
// 提示scoreboard开启
if(m_env_cfg.is_check) begin
`uvm_info("SCOREBOARD_ENABLED", "计分板已开启", UVM_MEDIUM)
end
endfunction
endclass
现在,env已经把env_cfg中的agent_cfg单独取出并发送给agent了,需要在agent处获取,并配置。
class my_agent extends uvm_agent;
`uvm_component_utils(my_agent)
my_sequencer m_seqr;
my_driver m_driv;
my_monitor m_mon;
// 声明agent_cfg的句柄
agent_cfg m_agent_cfg;
function new(string name = "", uvm_component parent);
super.new(name, parent);
endfunction
virtual function void build_phase(uvm_phase phase);
super.build_phase(phase);
// 这里是master agent,就不写判断条件了,最好是写上
m_seqr = my_sequencer::type_id::create("m_seqr", this);
m_driv = my_driver::type_id::create("m_driv", this);
m_mon = my_monitor::type_id::create("m_mon", this);
// 接收agent_cfg
if(!uvm_config_db#(agent_cfg)::get(this, "", "m_agent_cfg", m_agent_cfg);) begin
`uvm_fatal("AGENT_CONFIG_ERROR", "没有接收到来自ENV的配置类!")
end
// 继续往下传!
uvm_config_db#(virtual dut_interface)::set(
this, "m_driv", "driv_vif", m_agent_cfg.m_vif
);
uvm_config_db#(virtual dut_interface)::set(
this, "m_mon", "mon_vif", m_agent_cfg.m_vif
);
// 还有这个item_num要传给sequence
uvm_config_db#(int)::set(
this, "my_seqr", "item_num", agent_cfg.item_num
);
endfunction
endclass
传递vif这里只写driver的了,monitor的同理
class my_driver extends uvm_driver#(my_transaction);
`uvm_component_utils(my_driver)
virtual dut_interface m_vif;
function new(string name = "", uvm_component parent);
super.new(name, parent);
endfunction
virtual function void build_phase(uvm_phase phase);
super.build_phase(phase);
// 接收vif
uvm_config_db#(virtual dut_interface)::set(
this, "", "driv_vif", m_vif
);
endfunction
// 后面的代码就和之前没有区别了。
endclass
接下来是接收item_num的sequence,其实也和以前没什么大的区别:
class my_sequence extends uvm_sequence#(my_transaction);
`uvm_object_utils(my_sequence)
int item_num = 10;
function new(string name="");
super.new(name);
endfunction
virtual function void pre_randomize();
uvm_config_db#(int)::get(
my_sequencer, "","item_num",item_num
)
endfunction
virtual task body();
if(starting_phase != null) begin
starting_phase.raise_objection(this);
// 替换掉这里的数
repeat(item_num) begin
`uvm_do(req)
end
#100;
if(starting phase != null) begin
starting_phase.drop_objection(this);
end
end
endtask
endclass
而在顶层,需要在initial块中,配置好interface,并把它开始往下传,这点千万不要忘记。
initial begin
uvm_config_db#(virtual dut_interface)::set(null, "uvm_test_top", "vif", inf);
run_test("testcase");
end
最后强调一下,不论是set还是get,它的第一个参数都需要是一个component,千万不要忘记。
这一小节是整个这一章最困难的地方,后面的那些机制都没有这个难。但其实它并没有那么难,只是配置起来比较繁琐。工程中用到这种配置方法的机会可能也不是很多。
6.5 phase机制
UVM phase
UVM为平台组件定义了一套phase流程来控制仿真平台的执行过程,phase是uvm_component的属性。
下面是UVM phase的运行流程:

后面的描述需要看着这张图来理解。
为什么需要phase?
从验证平台的构建、配置到连接,再到运行,最后停止,需要有一定的先后顺序。
例如,在构建平台过程中,需要先实例化对象,配置对象,然后再连接各个组件。如果先连接组件,再实例化对象,就会出错。如果把实例化和配置打包成一个函数,再把连接打包成另一个函数,就可以确保按顺序执行。
每一个phase阶段都有一个任务或函数与其对应,例如实例化对应的是build_phase,等等。
同一个phase有两种顺序:
- 自顶向下(构造阶段):从树根root开始,自顶向下运行,直到每一个树叶。按照我的理解,这句话的意思是,在诸如build的阶段,需要不断地调用构造函数,必须先构造出env这样的容器类,才能继续向下构造agent这样的子对象;必须先构造出agent,才能继续构造sequencer、driver、monitor这样的子对象,所以是从树根到树叶。
- 自下向上(执行阶段):从树叶开始,一直到树根root。不同于构造连接阶段,执行阶段会从树叶开始,一直到树根。
task phase和function phase
task phase是会消耗仿真时间的,而function phase不消耗仿真时间。在上图中可以看出,只有执行阶段的run phase和12个runtime phase是task phase,其他的都是function phase。
task phase执行顺序
在准备阶段的start_of_simulation phase执行完成后,仿真会同时进入run_phase和pre_reset phase。也就是说,run phase和runtime phase是并行执行的。它们同时存在,可以共同使用。
而每一个组件的同名phase执行是会同步的。只有当每一个组件的同名phase全部执行完毕后,才会一起执行下一个phase,就算是function phase也一样。
未定义的phase
有些组件在某个phase中定义了功能,而其他组件没有在这个phase定义功能,不代表这些组件就不执行这个phase了。这些phase仍会执行,只是不具有任何功能。
phase的启动
只需要在顶层模块的initial块中执行代码run_test()启动验证平台,就可以自动启动phase了。只要将想要的功能对应写入这些phase,就会执行。
UVM task phase objection
objection是phase的属性,用来控制task phase的开始与结束。在先前的sequence代码中有这这样一对代码:
starting_phase.raise_objection(this);
starting_phase.drop_objection(this);
它们能控制task phase的开始和终止,同步components的同名task phase。objection可以在component或object中提起。每一次调用raise_objection都需要一个drop_objection与其对应。
使用时要注意:
- objection对task phase才有意义,控制task phase的开始和终止。
- 必须在执行消耗仿真时间的语句之前raise objection,否则整个phase都会失效。
- 在task phase结束时,需要调用drop objection,否则仿真会卡在这里,永不结束。
- 在某个component的phase中调用的raise_objection会启动其他的同名phase,drop同理。因此,在某个component中的phase中没有调用raise_objection并不一定导致它不启动,它可能会被其他component的同名phase启动。但是,如果在他运行完毕之前,提起raise_objection的phase已经调用了drop_objection,那么它会在没被执行完就终止,导致bug。所以原则上要求每一个需要运行的component都独立地调用一次raise_objection,而不是由其他component启动。
- 还有一点, objection只针对runtime phase,12个runtime phase只要有任何一个提起了objection,那么run phase也会跟着执行,不需要raise objection。

objection 使用方法总结
- 尽量在每个task phase都调用raise_objection和drop_objection
- 不要在无限循环的task phase中使用raise_objection和drop_objection
- 一定要成对使用raise_objection和drop_objection
- 每个task phase中尽量只使用一次
- raise_objection要在第一个消耗仿真时间的语句前使用
12个runtime phase的记忆方法
显然runtime phase可以分为4个阶段,reset、configure、main、shutdown,每个阶段又有pre、本身、post这三个阶段,很容易记得。
6.6 UVM信息服务机制
为了替代不方便使用的display函数,UVM提供了一系列信息打印服务。
优势:
- 可以显示打印信息在平台中的位置
- 通过层次、等级、时间等对打印信息进行过滤
信息安全等级
UVM的信息安全等级分为4个,FATAL、ERROR、WARNING、INFO。这四个等级对应不同的行为,每个安全等级都有默认的行为。
| 安全等级/仿真行为 | UVM_EXIT | UVM_COUNT | UVM_DISPLAY | UVM_LOG | UVM_CALL_HOOK | UVM_NO_ACTION | 安全等级描述 |
|---|---|---|---|---|---|---|---|
| UVM_FATAL | 默认行为2 | 默认行为1 | 不能容忍的错误,安全等级最严重 | ||||
| UVM_ERROR | 默认行为2 | 默认行为1 | 仿真本身的错误,例如scoreboard检查数据有误,无关平台 | ||||
| UVM_WARNING | 默认行为 | 警告信息,可能会影响仿真 | |||||
| UVM_INFO | 默认行为 | 一般的报告信息,安全等级最低 |
UVM_EXIT:立即终止仿真
UVM_COUNT:记录报告数量,达到设定的上限后自动停止仿真。上线设定方法:set_report_max_quit_count()
UVM_DISPLAY:在终端打印出相关信息
UVM_LOG:将相关信息写入指定文件中
UVM_CALL_HOOK:调用相关的回调函数
UVM_NO_ACTION:不会执行任何动作
四种安全等级的宏
`uvm_fatal("ID", "Message")
`uvm_error("ID", "Message")
`uvm_warning("ID", "Message")
`uvm_info("ID", "Message", verbosity)
除了info之外,其他的一定是会打印出来的,所以不需要冗余度。
uvm_info
`uvm_info("信息的ID", "打印的信息", 可视化等级)
可视化等级也被称为信息冗余度,可以在后面规定需要打印出来的最高等级,默认时,只有UVM_MEDIUM和UVM_LOW是会被打印的。
假如在一次测试中,增加了很多uvm_info,而后续的测试不需要这些info,可以调整冗余度可视程度,屏蔽掉这些信息。所以,需要提前搞清楚这些info的使用情况,安排一个统一的冗余度,免得需要一个一个注释。
可视化等级共有5种:UVM_LOW、UVM_MEDIUM、UVM_HIGH、UVM_FULL、UVM_DEBUG。一般只用前三个,后两个很少用。在UVM代码中,有这样一段代码:
typedef enum{
UVM_NONE = 0,
UVM_LOW = 100,
UVM_MEDIUM = 200,
UVM_HIGH = 300,
UVM_FULL = 400,
UVM_DEBUG = 500
} uvm_verbosity
运行仿真的时候可以可以指定可视化等级,在仿真命令里加入:+UVM_VERBOSITY=UVM_*
这是一条标准线,在这以上(不包括这个等级)的信息就会被屏蔽。
不止可以在仿真命令里进行全局限制,也可以用函数在component中设置:
// 只能设置当前组件info的可视化等级
set_report_verbosity_level(verbosity);
// 用来设置当前组件及当前组件的子组件info的可视化等级
set_report_verbosity_level_hier(verbosity);
自定义信息的默认行为
刚才的表格给出了每一种信息的默认行为,这些行为是可以修改的。
在testcase中的start_of_simulation_phase中可以用以下语句修改:
// 这句话是根据安全等级来修改行为的,覆盖面广,但优先级低,
// 可以被另外两种优先级更高的设置语句覆盖。
set_report_serverity_action(severity, action);
// 通过信息的ID改变行为。
set_report_id_action(ID, action);
// 根据安全等级+信息ID修改行为,它的覆盖范围最小,但却是优先级最高的行为修改语句。
set_report_severity_id_action(severity, ID, action);
看下面几条修改的例子:
// 这条语句会让INFO不再有任何操作,甚至不打印出信息
set_report_severity_action(UVM_INFO, UVM_NO_ACTION);
// 这条语句让ID为"DRV_RUN_PHASE"的信息只打印信息,没有其他后续行为,
// 不论他是否是FATAL。但如果它是INFO,则会覆盖上一条语句。
// 即使它是被设置为UVM_NO_ACTION的INFO,他也会照样打印出信息。
set_report_id_action("DRV_RUN_PHASE", UVM_DISPLAY);
// 这条语句会让类型为INFO的,具有"MON_RUN_PAHSE"的ID的信息触发时,直接退出仿真。
set_report_severity_id_action(UVM_INFO, "MON_RUN_PHASE", UVM_EXIT);
// 如果这样设置,那么不满足第二条和第三条条件的INFO语句,
//都不会有任何行为(因为最前面对UVM_INFO设置了UVM_NO_ACTION)
还有些其他的设置方法,但并不常用,工作中大概也不用这么复杂的设置,就不讲了。